First of all it is convenient to distinguish between concurrent and parallel processes:
Several processes are concurrent (at a certain time) if they are running simultaneously.
Several processes are parallel when they start running at the same time.
Parallel processes are concurrent while they are running. As processes terminate, concurrency (in number of processes) decreases until there is only one process or none left.
Concurrent processes interact with each other while they are running. This is why the number of possible execution paths can be very large and even the final result can be indeterminate.
A concurrent system is a set of processes that collaborate (to achieve a common goal) or compete with each other because each process pursues a particular goal.
Types of processes
Processes can be of two types:
Static. They are the ones explicitly created by the programmer.
Dynamic. They are processes created by other processes during the execution of a system.
A closed system is one in which all processes are static. An open system is one that has at least one dynamic process. In an open system, the number of running processes varies over time.
Concurrency Justification
The study of concurrency is justified by its great advantages:
It solves problems of a concurrent nature such as: operating systems, control systems, client/server systems, database management systems, web browsers, e-mail, chat rooms, etc. In general, systems that serve users and programs are designed to run indefinitely.
Improves the performance of a system's execution, as processes can cooperate with each other to share the workload.
Provides a more flexible and natural model of application design.
Facilitates the development of complex systems.
Allows to optimize the use of resources.
Implementation of concurrent scheduling
Concurrency programming (also called concurrency engineering) has traditionally been approached in two ways:
Using a language that supports concurrency, such as Ada or Java.
Using the concurrency software resources of the operating system. They are usable from several languages.
In general, the underlying complexity of concurrency is often hidden from the programmer.
Theoretical models of concurrent systems
There are many theoretical models of concurrent systems. The most prominent ones are:
Petri Nets.
They are acyclic oriented graphs with two classes of nodes: places and transitions. Arcs link a locus to a transition or vice versa. Petri nets were one of the first models (dating back to the 1960s).
Process algebra.
A family of approaches that provide tools for a high-level description of communications, interactions and synchronization between processes. Communications are carried out by means of messages via channels. The algebra is based on a small set of primitives and operators that allow combining these primitives. An example of process algebra is CSP (Communicating Sequential Processes), presented by Hoare in 1978.
SCOOP (Simple Concurrent Object Oriented Programming).
It is a concurrency model designed for the Eiffel language, conceived by the creator of Eiffel (Bertrand Meyer). Its goal is to facilitate the development of concurrent programs with almost the same additional effort as non-concurrent (centralized and distributed) programs.
The great variety of theoretical models has motivated some researchers to search for a possible unification and a standard that does not exist today. Currently concurrency theory is a very active area of research.
Types of inter-process communications
Inter-process communications can be of two types:
Asynchronous.
A source process p1 sends information to another destination process p< sub>2, and p1 does not wait for the response from p2. Only one primitive is used: Send (send).
For example, Internet crawlers make http-like requests to get pages. The incoming responses are accumulated and then analyzed. The process is not deterministic because the responses are not necessarily received in the same order as the requests.
Synchronous.
A source process p1 sends information to another process p2, and p1 waits for p2's response before continuing the process. Two primitives are used: Send and Wait.
Examples of synchronous communications are in general client-server systems such as: web servers, database servers, transaction servers or requests associated with user mouse clicks on the GUI (graphical user interface), etc.
In both cases, the information consists of data and the identification (or signal) of the source process. In the case of synchronous communications, the signals serve for synchronization.
Communication mechanisms between concurrent processes
There are two, mainly:
The passing of messages between processes.
The common memory path between processes.
In both cases, communication can be synchronous or asynchronous.
In centralized systems a common memory (environment) is shared and processes can communicate indirectly through this common memory. In distributed systems there is no shared memory, there are several environments, and communication has to be implemented by message passing.
The use of events is the form of concurrency management that has proven to be the most effective.
Resource sharing between processes
One possible implementation may be using a queuing type mechanism:
The process that wants to access the resource is put in a queue.
The process is stopped waiting for access to the resource (in active queue).
The queue is served following a FIFO policy (First In, First Out). The process servicing the queue gives it access to the resource.
The process exits the active queue and the process continues its normal execution.
Execution environments
There are three execution environments:
A single-processor system with multiprogramming.
In multiprogramming several processes are hosted in main memory and executed by a single CPU.
A multiprocessor system with shared memory.
Each processor serves one process.
A distributed system.
In this case there is no shared memory, so communication must be done by messages.
Implementation of concurrent systems
Process concurrency requires a manager mechanism or operating system that distributes the available resources over the processes. The most prominent ones are:
Time slicing.
The single CPU time is divided into n equal intervals (n processes) and the system allocates resources cyclically among the processes. Each process has the "impression" that it is running on a real machine dedicated to that process. It is said that each process is served by a "virtual machine". It is a pseudo-parallelism, as there is no real physical parallelism.
Threads of execution.
A thread is the smallest processing unit that can be managed by an operating system. Threads make it possible to run a system concurrently. A thread is simply a task that can be executed at the same time as another task. Each thread or process runs on its own virtual processor. The different threads share system resources. A process is composed of several independent threads. The threads use memory to communicate with each other, but each thread uses a virtual address space.
Fork system.
In this case no threads are used. The memory is divided between the different processes. It is a safer system than threads.
Specification in MENTAL
We approach the topic of concurrency from a theoretical point of view, without reference to possible concrete implementations (processors, memory spaces, etc.). Theoretical or mental (non-physical) concurrency is more general than physical concurrency, since the design of programs is not conditioned by the available computational resources.
MENTAL, unlike other languages, does not need any special theoretical resources for the design of concurrent programs. The language primitives are enough. If it needed additional special resources, it would not be a universal language. With MENTAL, concurrency programming is simpler and more intuitive. Interrupts, communications and process synchronization are expressed in a high-level language.
MENTAL is the natural concurrency model. It is the "mother" model from which all other particular models emerge.
In MENTAL we do not distinguish between process and task because the mechanism in both cases is identical: when a process is divided into several tasks or when a system is divided into several processes. From now on we will use only the terms "system" and "process".
Communication between processes
Communication between processes is done through abstract space. It is the simplest mechanism of communication. Synchronization is done through events. A process deposits a value in a variable and a generic expression triggers another process when the variable takes a given value or values.
Examples of process synchronization
Pure synchronization.
We want to synchronize two processes p1 and p2, so that they begin to execute at the same time. For it we create a variable s (of "synchronization"), so that if s=1, p1 and p2 begin to be executed in parallel:
⟨( s=1 → (s=0 {p1 p2} )⟩
The restoration of s is important, because if it were not done, the parallel execution of the two processes would be started at all times. This notation has the advantage that the execution of the two processes can be started repeatedly (each time we do s=1).
Passive and active waits of a process.
A process is passively waiting if it is waiting to be explicitly invoked to run.
A process is in active standby if, at all times, it is checking if a certain condition is verified to start executing. The expression to apply is the following:
⟨( condition → process )⟩
For example, a process A must wait for process B to finish before it can continue its execution. If the task B indicates that it has finished by b=1, and we call A1 the previous task and A2 the continuation of the task A when B ends, we have a wait loop in the code that separates A1 and A2:
(wait = (wait ←' b=1 → A2)))
Parallel expressions
Are those that appear associated with the primitive "parallel group" or set. Examples:
Evaluations or parallel executions of three expressions.
{p1 p2 p3}
Parallel conditions.
{x←a y←b z←c}
Parallel sums.
The (non-concurrent) serial expression a+b+c+d can be expressed as
({(s1 = a+b) (s2 = c+d)} (s1+s2)¡)!
Full concurrency is not possible in this case, due to the very nature of the operation.
Parallel relative substitution.
(a a+4 b b+8)/{a=1 b=2} ev. (1 5 2 10)
Process structures
A set of processes running in series is specified by a serial (sequence) expression. For example,
p=(p1 p2 p3 p4)
where first p1 is executed; when it finishes, p2; etc. is started.
A set of processes running in parallel is specified by a parallel expression (set). For example,
p={p1 p2 p3 p4}
Where the processes p1, p2, p3 and p4 start executing at the same time.
Using these two primitives (sequence and set) and their combinations we can specify different process structures. Examples:
(q1 {p1 p2 p3} q2)
First, q1 is executed; when it finishes, the processes p1, p2 and p3 are executed in parallel; when these last three processes finish, then q2 begins to be executed.
{p1 {p21 p22} p3}
There is initial synchronicity between the 4 processes, so this expression is equivalent (only from the concurrent point of view) to {p1 p21 p22 p22 p3}.
Interactions between processes
A process p1 can interact with another process p2 in the following ways:
Affecting its execution flow by means of the actions:
Starting process p2: p2!
End process p2: p2¡
Stop process p2: (■ p2)
Continue process p2: (▶ p2)
Modifying your code dynamically.
Updating shared expressions (usually variables).
Remarks:
The operation "Stop" (■) is a primitive of MENTAL. Its opposite (■'= ▶) is "Continue".
If p is a stopped process, ■p has no effect.
If p is a running process, &9654;p has no effect.
There can obviously be mutual interaction between the two processes.
When two processes do not interact with each other in any way, they are called "disjoint".
A process p1 can stop another process p2 directly. A typical situation occurs when the process p1 wants to perform, from a certain time, a certain task without being "disturbed" or affected by the other process. To do this, what it does is:
Stop the process p2: (■ p2).
Run process p1.
Resume process p2: (▶ p2).
It is possible to know the state of a process by assigning values to state variables. For example, at the beginning of the process p, we do for example (ejec(p) = 1) and at the end of the process we do (ejec(p) = 0). By asking for this variable we can know its state: in execution or not.
Design of concurrent process systems
This is done by means of precedence diagrams, in which the following representation is used
to indicate that p1 must be executed before p2. It is coded (p1 p2).
When two processes appear in the same vertical, they indicate parallelism. It is coded {p1 p2}.
The design is going to depend on the granularity (large or small) of the processes.
Examples:
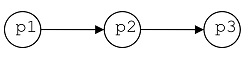
The diagram
can be represented by the sequence (p1 p2 p3)
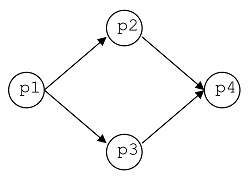
The diagram
Where processes located in the same vertical run in parallel. It can be represented by (p1 {p2 p3} p4)
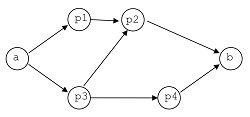
The diagram
we can express it by a combination of serial and parallel expressions, together with generic expressions that establish the execution priority conditions of the processes:
This version uses only one variable, which is the parameter n.
Variables in processes
To avoid confusing variables with the same name and belonging to different processes, a possible solution is to use the notation x(p), where x is the process variable p.
When several processes can concurrently access a shared resource (e.g., a variable), the problem arises that only one process at a time should access that resource. This is called "mutual exclusion".
Numerous solutions to this problem have been proposed. The most advisable is to perform a generic parameterized procedure that solves the problem in a safe way for any process and any variable.
A process needs to update the data (value) of the variable x and another process also tries to do the same. The first process that is going to perform the update must lock the update code and unlock it after the update.
⟨( access(x° data) =
(lock(x°) := 0) // initial value (unlocked)
(z° = (lock(x°) = 1) → z) // wait until unlocked
(lock(x°) = 1) // block
(x° = data) // update variable x
(lock(x°) = 0) // unlock
)⟩
Example: access(v° 23)
We assume that it is impossible (at a theoretical level) for several processes to execute this code simultaneously, since simultaneity is only possible by means of a parallel expression.
An example of a shared variable is as follows. An enclosure has several entrances, with a turnstile at each entrance, which counts the number of visitors entering. There is a counting process for each entrance. The problem is to know at all times the total number of visitors that have entered the enclosure. If all the processes share the same memory, the variable that totals the number of visitors at all times is
⟨( n = n1 + ... + nk )⟩
where ni is the counter of the lathe i and k is the number of entries. This expression, being generic, is always being evaluated, so the solution is extremely simple.
Addenda
OpenMP (open Multiprocessor)
It is the de facto standard for parallel programming on shared memory systems. It is an API for a multiprocess programming environment with memory sharing. It consists of a set of routines, compilation directives and environment variables. It provides a simple and flexible interface for parallel application development. OpenMP has been implemented in many compilers and various operating systems, including Windows and Unix.
OpenMP is based on the fork-join model, a model that comes from Unix systems, where a large task is subdivided into several smaller subtasks (or threads) that run in parallel, and then "collect" the results obtained from each task and join them into a single final result.
Appearance of blockages in processes
In concurrent programming, deadlocks can occur as a result of unforeseen problems:
Passive deadlock.
All processes are waiting for an event to occur that will never occur.
Active interlock (livelock).
Processes execute instructions, but there is no effective progress.
Starvation.
Occurs when a process waits indefinitely for resources to be provided.
A brief history of concurrent programming languages
Initially, concurrent programming was done in assembly language, at a low level.
In 1972 the first high-level language supporting concurrency appeared: Concurrent Pascal [Brinch-Hansen, 1975]. It was created as a tool for the design and implementation of operating systems.
In 1978 Hoare developed CSP (Communication Sequential Process) for distributed systems.
In 1980-81, Niklaus Wirth developed Modula-2, a direct descendant of Pascal and Modula.
In 1980 the Ada language incorporated concurrency into the language statements.
In 1981 Concurrent Euclid appeared, aimed at developing reliable and efficient concurrent software.
Java, a recent object-oriented language, supports concurrent programming through specific primitives.
Bibliography
Arnold, André; Beauquier, Joffroy; Bérard, Béatrice; Rozoy, Brigitte. Programas paralelos. Modelos y Validación. Paraninfo, 1994.
Birrell, Andrew D. An Introduction to Programming with Threads. Digital Systems Research Center, 1989. Disponible online.
Brinch-Hausen, P. The programming language Concurrent Pascal. IEEE Transaction on Software Engineering, 1 (2): 199-207, 1975.
Drake, José María. Computación Concurrente. Internet.
Palma Méndez, José Tomás; Garrido Carrera, Mª del Carmen; Sánchez Figueroa, Fernando; Quesada Arencibia, Alexis. Programación Concurrente. Thomson, 2003.
Pérez Martínez, Jorge E. Programación concurrente. Editorial Rueda, S.L., 1990.
Tanenbaum, Andrew S. Operating Systems (Design & Implementation). Prentice-Hall, 1987.